个人版知识库FastGPT部署教程
个人版知识库FastGPT部署教程
noise
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
记得踩坑前到官方的https://github.com/labring/FastGPT/issues处查看他人遇到的问题
前言
需要准备一台配置不算低且容量大点的云服务器或本地部署,部署前要考虑好对接向量模型是调用在线GPT模型API还是离线化的向量模型,FastGPT文档检索默认对接OPEN AI的text-embedding-ada-002模型,官方也介绍了其他模型的对接,如果你考虑离线化模型可以先部署模型,另外最好先部署好One API 项目【https://github.com/songquanpeng/one-api】
官方接入微软、ChatGLM、本地模型等文档:https://doc.fastgpt.in/docs/development/one-api/
我自己部署的一些容量占比参考:
fastgpt:latest 镜像大小:349.65 MB
mongo:5.0.18 镜像大小:632.08 MB
one-api:latest 镜像大小:46.20 MB
pgvector:v0.5.0 镜像大小:394.77 MB
reranker:v0.1 模型镜像大小:7.65 GB
M3E模型镜像大小:6.95GB
M3E文本转向量模型的部署
M3E 是 Moka Massive Mixed Embedding 的缩写
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量+
原项目地址:https://huggingface.co/moka-ai/m3e-large
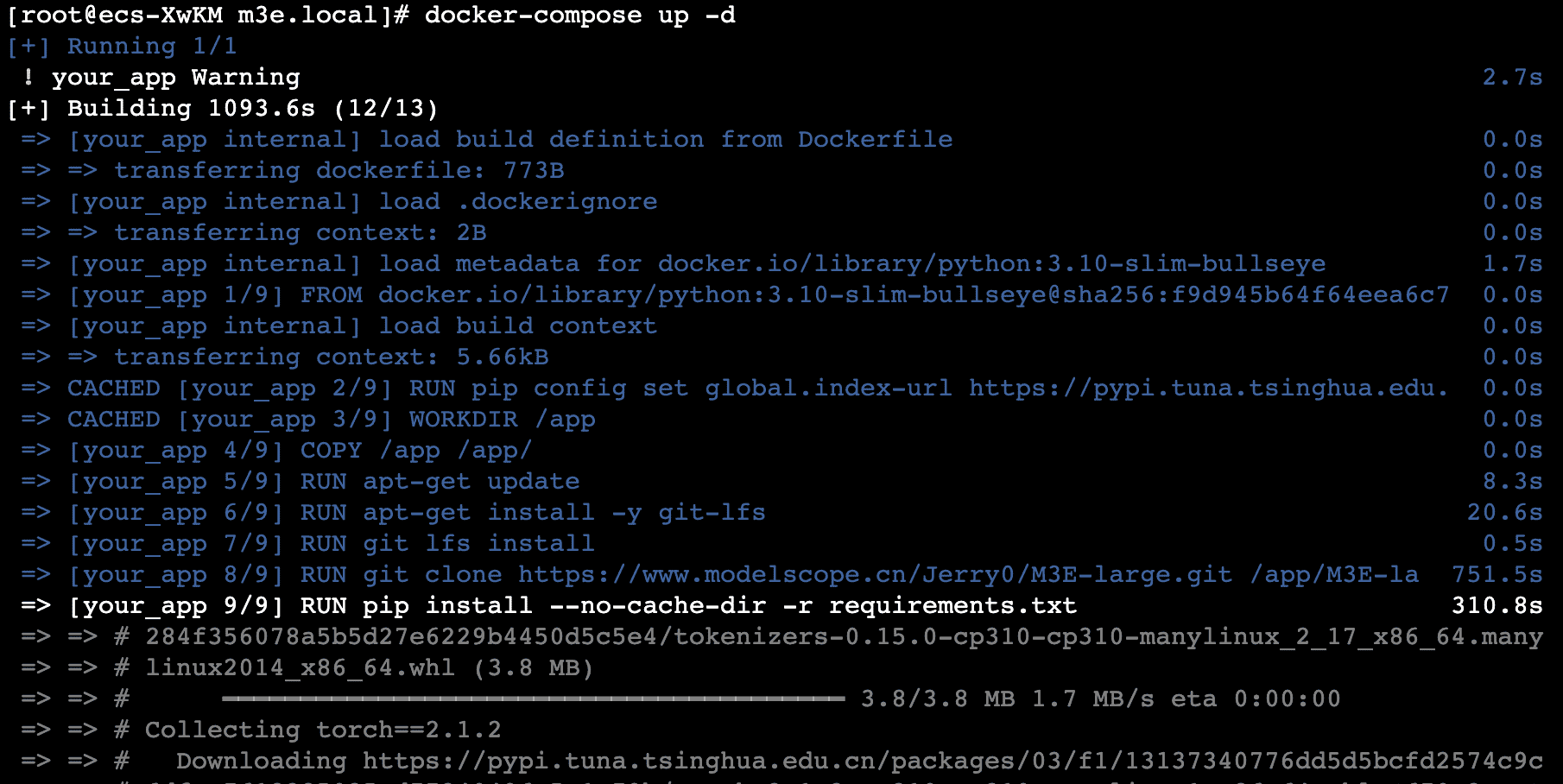
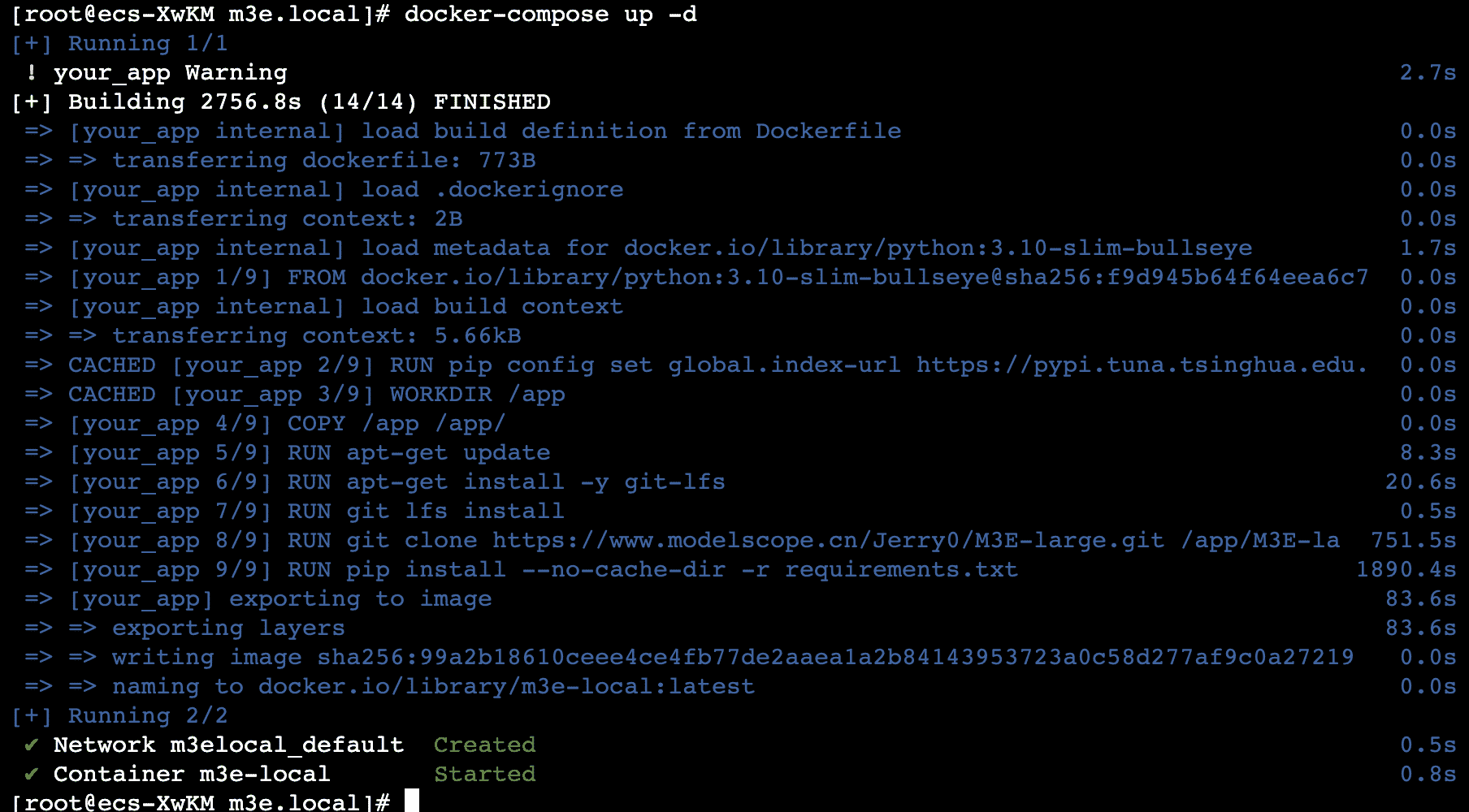
兼容openapi的text-embedding-ada-002接口服务Docker部署(存在容器里):
项目地址:https://github.com/fanfpy/m3e.local
使用方法
1 | git clone https://github.com/fanfpy/m3e.local.git |
验证
request
1 | curl --location 'http://127.0.0.1:6006/v1/embeddings' \ |
response
1 | { |
接入 One API
在oneapi里填的是IP+docker-compose.yml中设置的端口
秘钥为:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
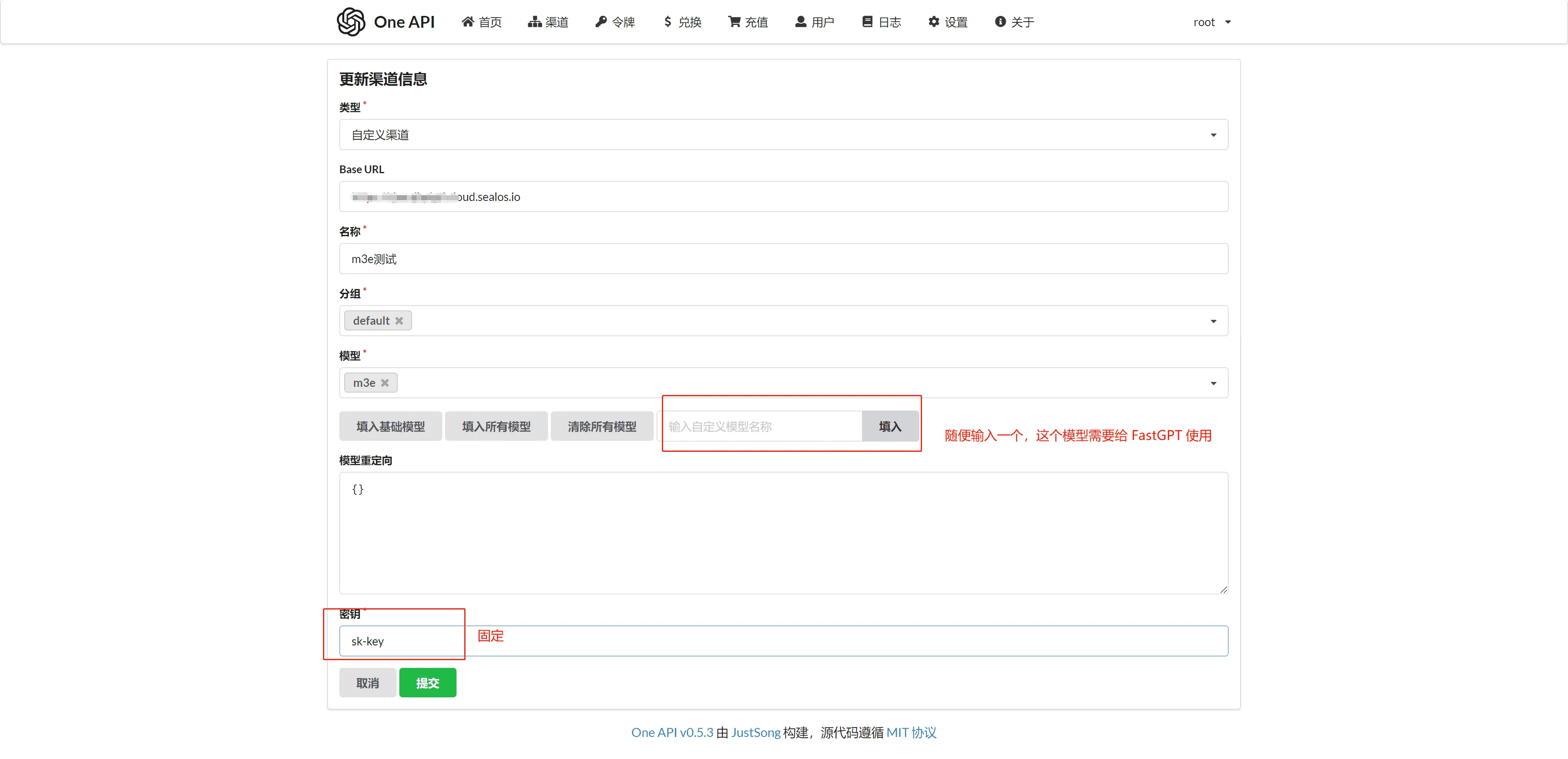
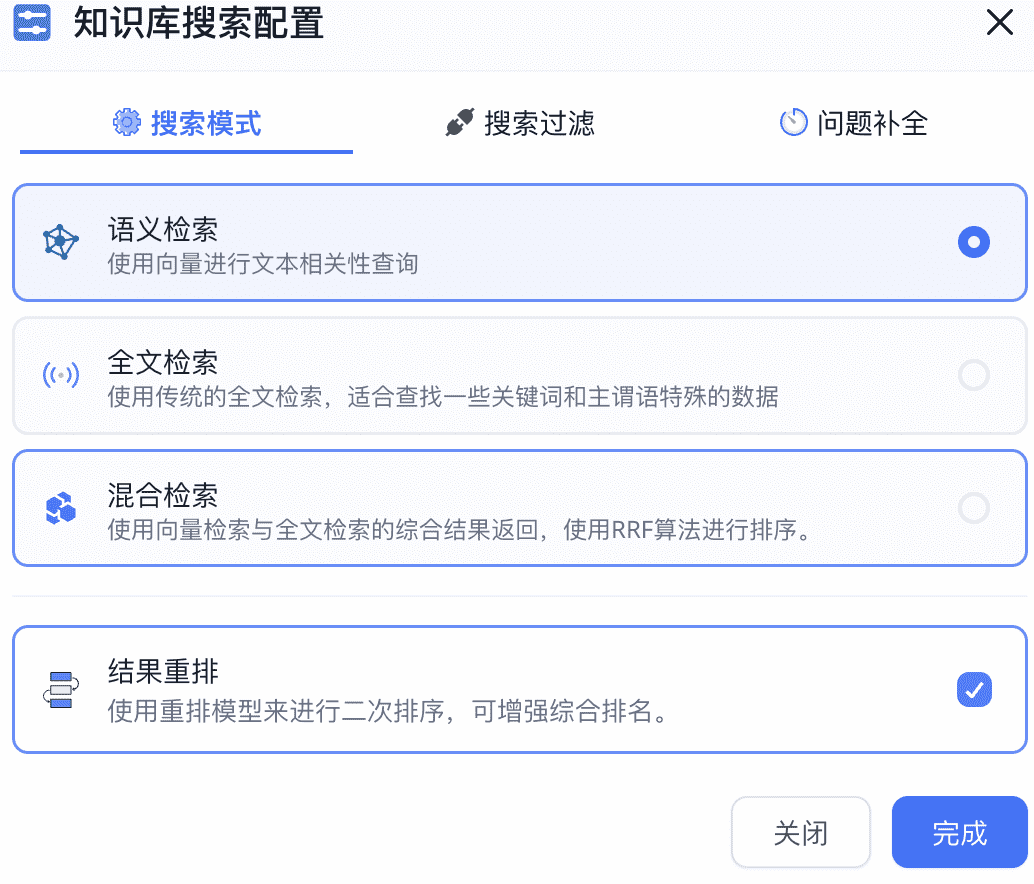
接入 FastGPT
修改 config.json 配置文件,在 vectorModels 中加入 M3E 模型:
1 | "vectorModels": [ |
接入 ChatGLM2-6B及ReRank 重排模型
环境要求
- Python 3.10.11
- CUDA 11.7
- 科学上网环境
源码部署
- 根据上面的环境配置配置好环境,具体教程自行 GPT;
- 下载 python 文件
- 在命令行输入命令
pip install -r requirements.txt; - 按照https://huggingface.co/BAAI/bge-reranker-base下载模型仓库到app.py同级目录
- 添加环境变量
export ACCESS_TOKEN=XXXXXX配置 token,这里的 token 只是加一层验证,防止接口被人盗用,默认值为ACCESS_TOKEN; - 执行命令
python app.py。
然后等待模型下载,直到模型加载完毕为止。如果出现报错先问 GPT。
启动成功后应该会显示如下地址:

这里的
http://0.0.0.0:6006就是连接地址。
docker 部署
- 镜像名:
luanshaotong/reranker:v0.1 - 端口号: 6006
- 大小:约8GB
设置安全凭证(即oneapi中的渠道密钥)
1 | ACCESS_TOKEN=mytoken |
运行命令示例
- 无需GPU环境,使用CPU运行
1 | docker run -d --name reranker -p 6006:6006 -e ACCESS_TOKEN=mytoken luanshaotong/reranker:v0.1 |
- 需要CUDA 11.7环境
1 | docker run -d --gpus all --name reranker -p 6006:6006 -e ACCESS_TOKEN=mytoken luanshaotong/reranker:v0.1 |
docker-compose.yml示例
1 | version: "3" |
接入 FastGPT
1 | "reRankModels": [ |
ChatGLM2-6B部署
推荐配置
依据官方数据,同样是生成 8192 长度,量化等级为 FP16 要占用 12.8GB 显存、int8 为 8.1GB 显存、int4 为 5.1GB 显存,量化后会稍微影响性能,但不多。
因此推荐配置如下:
| 类型 | 内存 | 显存 | 硬盘空间 | 启动命令 |
|---|---|---|---|---|
| fp16 | >=16GB | >=16GB | >=25GB | python openai_api.py 16 |
| int8 | >=16GB | >=9GB | >=25GB | python openai_api.py 8 |
| int4 | >=16GB | >=6GB | >=25GB | python openai_api.py 4 |
环境要求
- Python 3.8.10
- CUDA 11.8
- 科学上网环境
源码部署
- 根据上面的环境配置配置好环境,具体教程自行 GPT;
- 下载 python 文件
- 在命令行输入命令
pip install -r requirements.txt; - 打开你需要启动的 py 文件,在代码的
verify_token方法中配置 token,这里的 token 只是加一层验证,防止接口被人盗用; - 执行命令
python openai_api.py --model_name 16。这里的数字根据上面的配置进行选择。
然后等待模型下载,直到模型加载完毕为止。如果出现报错先问 GPT。
启动成功后应该会显示如下地址:

这里的
http://0.0.0.0:6006就是连接地址。
docker 部署
镜像和端口
- 镜像名:
stawky/chatglm2:latest - 国内镜像名:
registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/chatglm2:latest - 端口号: 6006
1 | # 设置安全凭证(即oneapi中的渠道密钥) |
接入 One API
为 chatglm2 添加一个渠道,参数如下:

这里填入 chatglm2 作为语言模型
测试
curl 例子:
1 | curl --location --request POST 'https://domain/v1/chat/completions' \ |
Authorization 为 sk-aaabbbcccdddeeefffggghhhiiijjjkkk。model 为刚刚在 One API 填写的自定义模型。
接入 FastGPT
修改 config.json 配置文件,在 llmModels 中加入 chatglm2 模型:
1 | "llmModels": [ |
FASTGPT本体部署
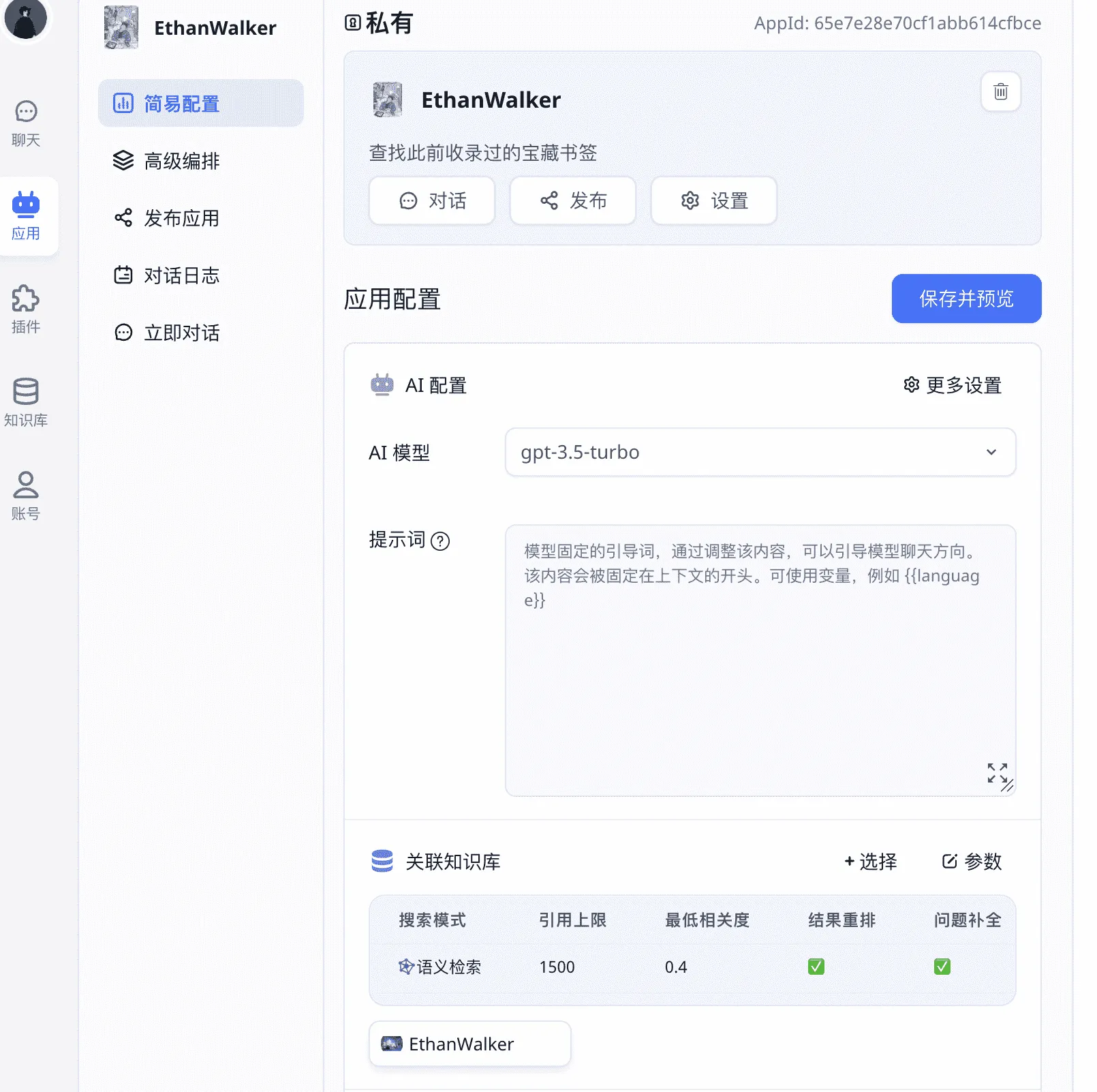
第一步:修改docker-compose.yml 代码
修改docker-compose.yml 里mongo部分的代码,补上command和mongodb.key
1 | mongo: |
windows下不能修改权限时将内容替换为:
1 | mongo: |
第二步:修改config.json代码:
直接复制以下代码替换掉原来的:
1 | { |
第三步:创建 mongo 密钥,赋予密钥文件权限:
打开终端, CD 进项目的目录,如果安装了宝塔,直接在项目的目录界面点击终端。
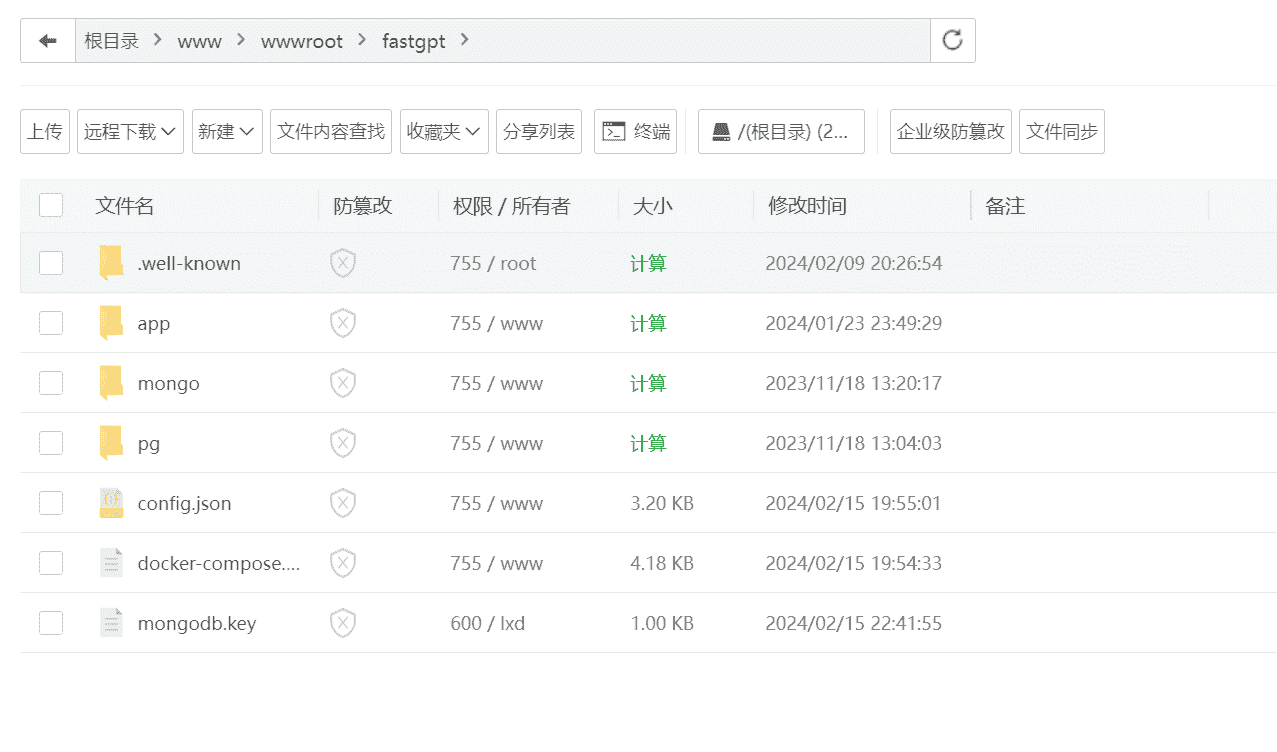
在终端输入代码:
1 | openssl rand -base64 756 > ./mongodb.key |
接着再输入:chmod 600 ./mongodb.key
接着再输入:chown 999:root ./mongodb.key
(!!!这一步很关键,如果不输入这一步,就无法启动Mongo容器)
第四步:重启所有容器。
依次在终端输入以下代码:
1 | 重启 Mongo |
此时,可以去Docker界面看看mongo是否正常启动,如果没有启动,就手动启动一下。
第五步:进入容器初始化部分集合
先在终端输入:
docker exec -it mongo bash再输入:
mongo -u myname -p mypassword --authenticationDatabase admin(注意这里的
myname和mypassword,要和docker-compose.yml里mongo部分的代码一致。)初始化副本集。在终端输入以下代码:
1
2
3
4
5
6rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})检查状态。
输入:rs.status()如果提示rs0状态,则代表运行成功
第六步:更新容器
在终端输入以下代码:
1 | docker-compose down && docker-compose pull && docker-compose up -d |
其它问题:
1、导入知识库时提示null value in column "tmb_id" of relation "modeldata" violates not-null constraint
这可能是因为没有初始化4.6.7,或初始化4.6.7出现了某首错误,比如rootkey不正确;
2、已经显示4.6.8,但对话或导入模型时提示没有模型。
需要重新拉取最新的容器:
1 | docker-compose down && docker-compose pull && docker-compose up -d |
3、初始化mongo副本集提示This node was not started with the replSet option
这是因为mongodb.key的权限不够,需要再在终端输入:chown 999:root ./mongodb.key
4、Docker部署m3e向量模型时报错【选择国内镜像或从huggingface下载后调用】
5、部署FAST-GPT时登录报错【一般是key权限问题】
6、MongoDB 容器并配置副本集初始化报错【docker exec -it mongo mongo 然后,在 MongoDB Shell 中执行 rs.initiate() 命令来初始化副本集:rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "localhost:27017" }
]})
】
6、报错:Operation users.findOne() buffering timed out after 10000ms
mongo运行失败的结果,需要初始化副本集后再启动