LLaVA-免费体验最新的GPT-4图文识别
LLaVA-免费体验最新的GPT-4图文识别
noise介绍
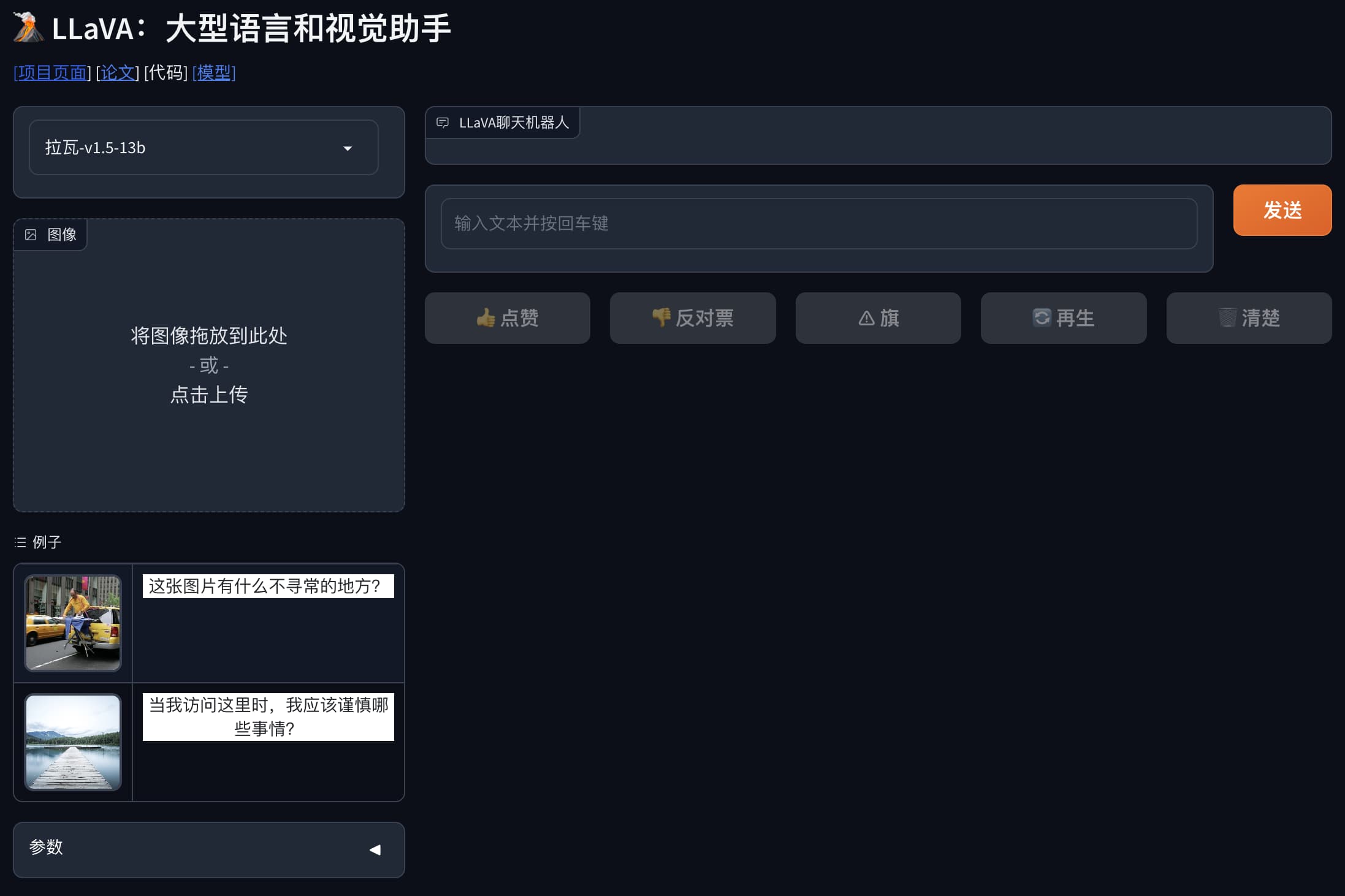
LLaVA代表了一种新颖的端到端训练大型多模态模型,对于通用的视觉和语言理解, 实现令人印象深刻的聊天功能,提供了多模式 GPT-4 的形态使用
地址
访问: https://llava-vl.github.io/
GitHub:https://github.com/haotian-liu/LLaVA
特征
- 多模式指示数据。首次尝试使用纯语言 GPT-4 生成多模态语言图像指令跟踪数据。
- LLaVA模型。介绍了LLaVA(L arge Language-a nd-Vision Assistant),这是一个端到端训练的大型多模态模型,连接视觉编码器和LLM以实现通用视觉和语言理解。
- 性能。早期实验表明,LLaVA 表现出令人印象深刻的多模型聊天能力,有时会在看不见的图像/指令上表现出多模态 GPT-4 的行为,并且在合成多模态指令遵循数据集上与 GPT-4 相比产生了 85.1% 的相对分数。 当对科学 QA 进行微调时,LLaVA 和 GPT-4 的协同作用达到了 92.53% 的新先进准确度。
- 开源。公开提供 GPT-4 生成的可视化指令调整数据、我们的模型和代码库。



喜欢这篇文章的人也看了



评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果